We all have intensely personal relationships with Google. The questions we ask of it can, in many ways, tell the story of our lives. Ranging from questions about our work to our hobbies to our fears, many people are honest with Google in a way they are with a select few. I recently found out that Google allows users to download a record of the search queries in easily digestible JSON, and I immediately knew that this would be the topic of my next blog post. Pretending that I know nothing about myself, what can I learn about my life by looking through my search history? In part one of this two-part post, I'll explore the general themes present in my queries. What words appear the most often in my searches? How have my searches changed over the past two years? How about over the course of a week? Let's find out.
Data
I was able to download a little less than two years worth of my search queries by following the guide here. Google provides individual JSON files for each financial quarter containing the timestamp and content of each query. Map queries are included as well. Unfortunately, they are not clearly labeled, so I was unable to exclude them. Direction queries, however, all contained '->', so I removed all queries containing that arrow.
The first query in my database was performed on July 28, 2013, and these data were collected on June 22, 2015. I'm not sure why Google only has two years worth of data available on me. Presumably, I deleted my entire history in July, 2013, though I don't remember doing so. While all the other datasets used on this blog have been publicly available or been made available by me, I am going to keep this dataset to myself for privacy reasons. In total, this dataset comprises 22,339 search queries.
Results
What words appear the most often in my searches?
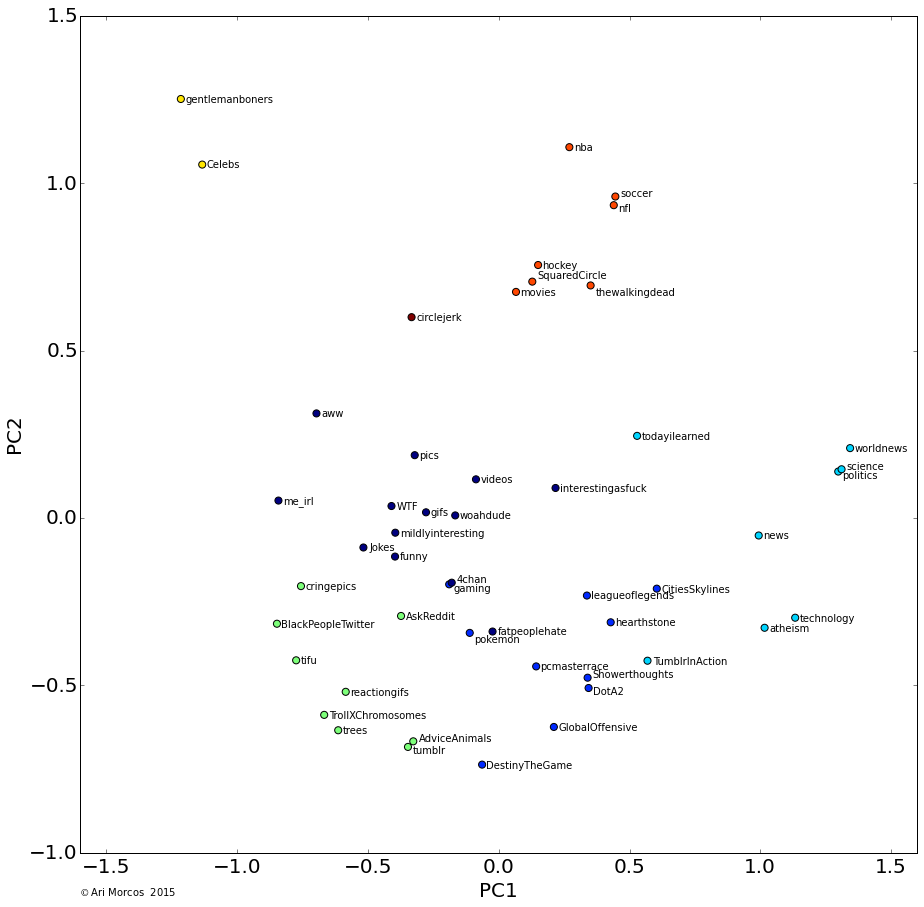
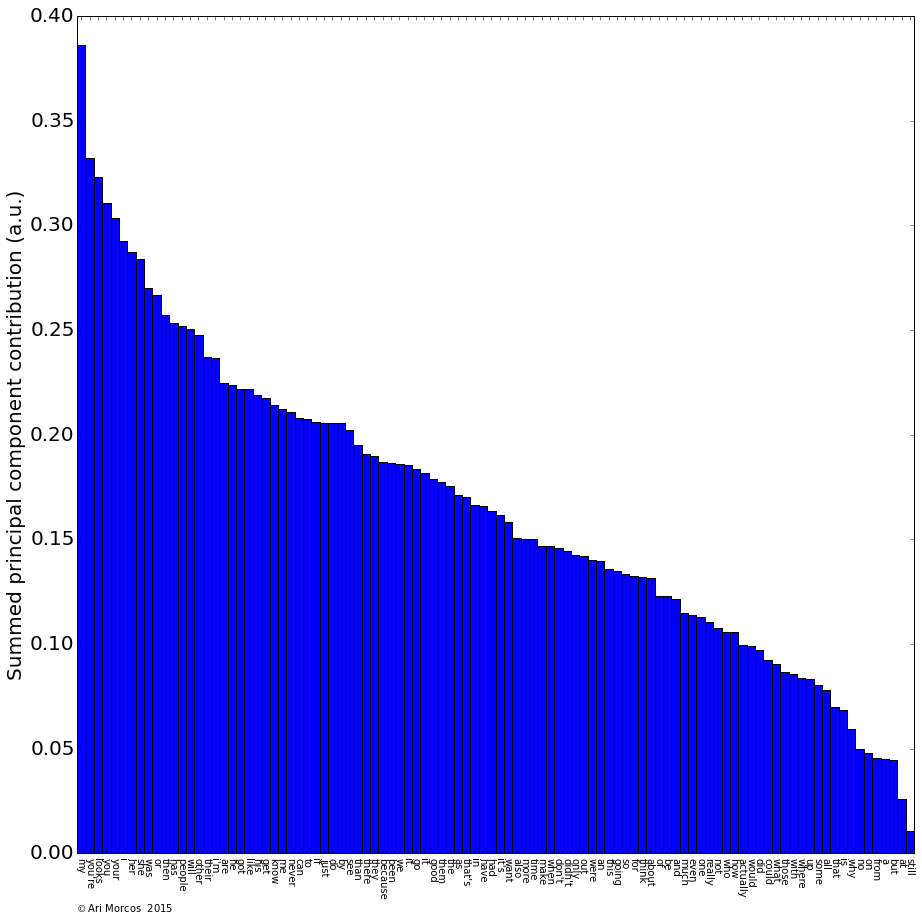
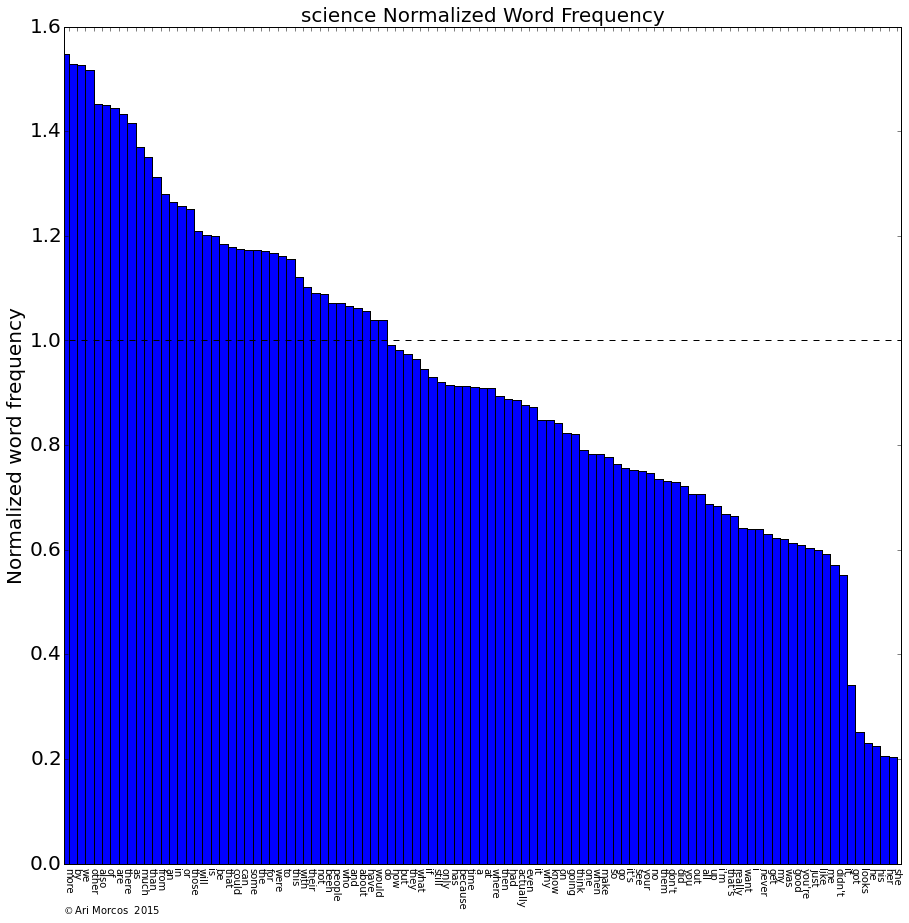
For this exercise, I'm going to take a naive approach to the data. In other words, I'm going to pretend that I know nothing about myself. To start with, what words appear in my queries most often? As a pre-processing step for this question (and the questions below), I tokenized each query into individual words, removing punctuation. I also converted all words into lowercase to remove case conflicts. To calculate the frequency of each word, I simply used the Natural Language Toolkit (NLTK) object, FreqDist. For this analysis, I also removed common, uninformative, words, such as conjunctions and articles. Let's take a look at the fifty words that appear most often in my search queries.
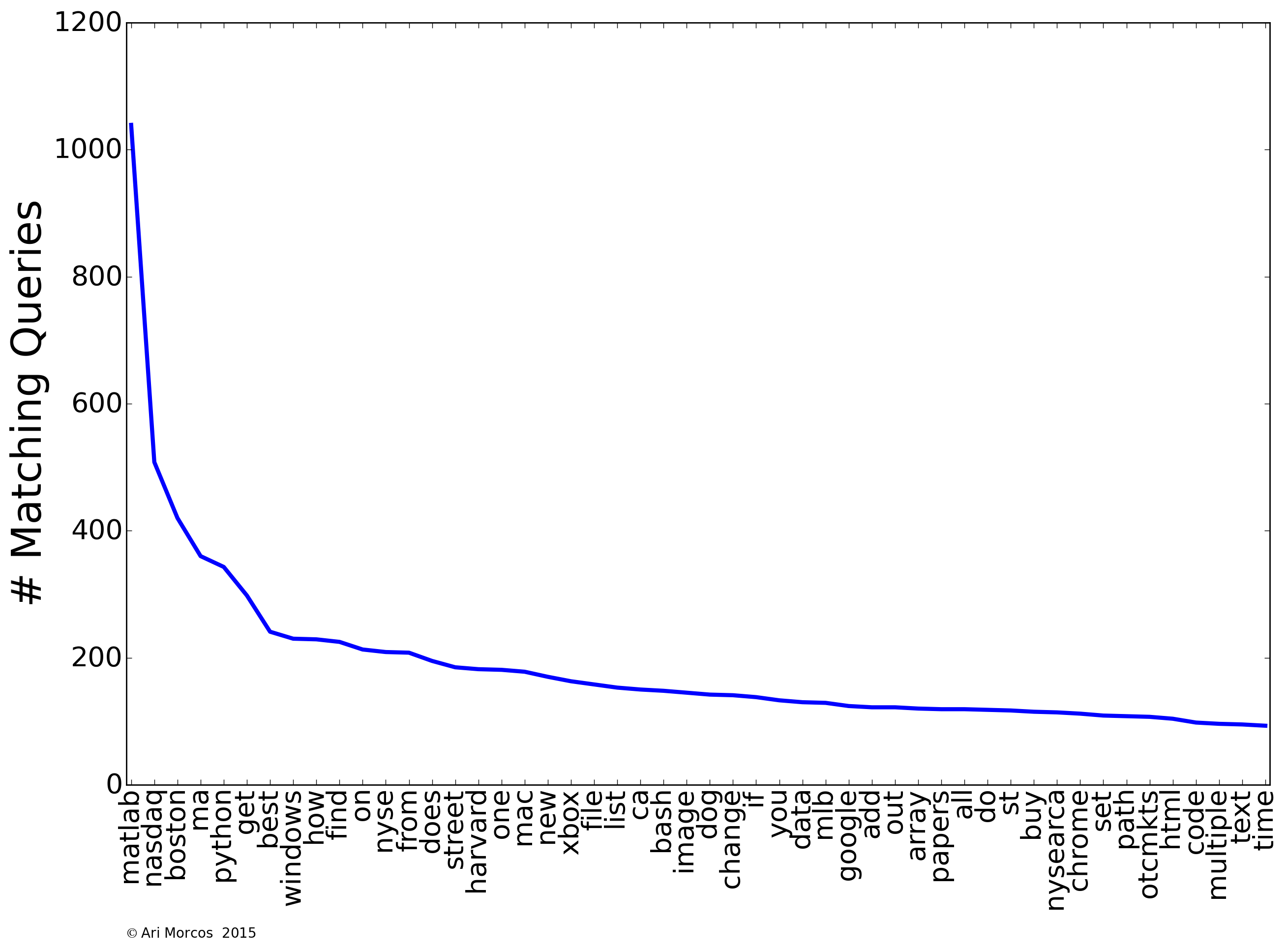
A few themes immediately jump out. First and foremost, my most searched for word, by a large margin, is "matlab." As a neuroscientist working in academia, I spend the majority of my day coding in Matlab, so this makes sense. You can also see several other programming related words pop up with high frequency, including "python," "bash," "array," "html," and "list." We also see another theme: finance. Financial words abound, including "nasdaq," "nysearca," and "nyse." There are also words relating to video games (e.g., "xbox"), operating systems (e.g., "windows"), and baseball (e.g., "mlb").
It is also obvious that I live in Boston and attend Harvard, as "boston" and "ma" are two of the four most frequently used words, and "harvard" comes in at #16.
How have my searches changed over time?
From looking at the frequency distribution, I was able to tease out several obvious themes in my searches. Are searches for these themes constant throughout time, or has their frequency changed over the past two years? To find out, I binned the data into individual months, and counted the number of queries in each bucket containing words related to the theme of interest. As an example, for the "Web Development" theme, I included "html" and "css" as relevant search terms. Note that each query can only be counted once, so a query containing both of these words would not be double-counted. Below, I've plotted the number of matching queries over time for several of the above categories.
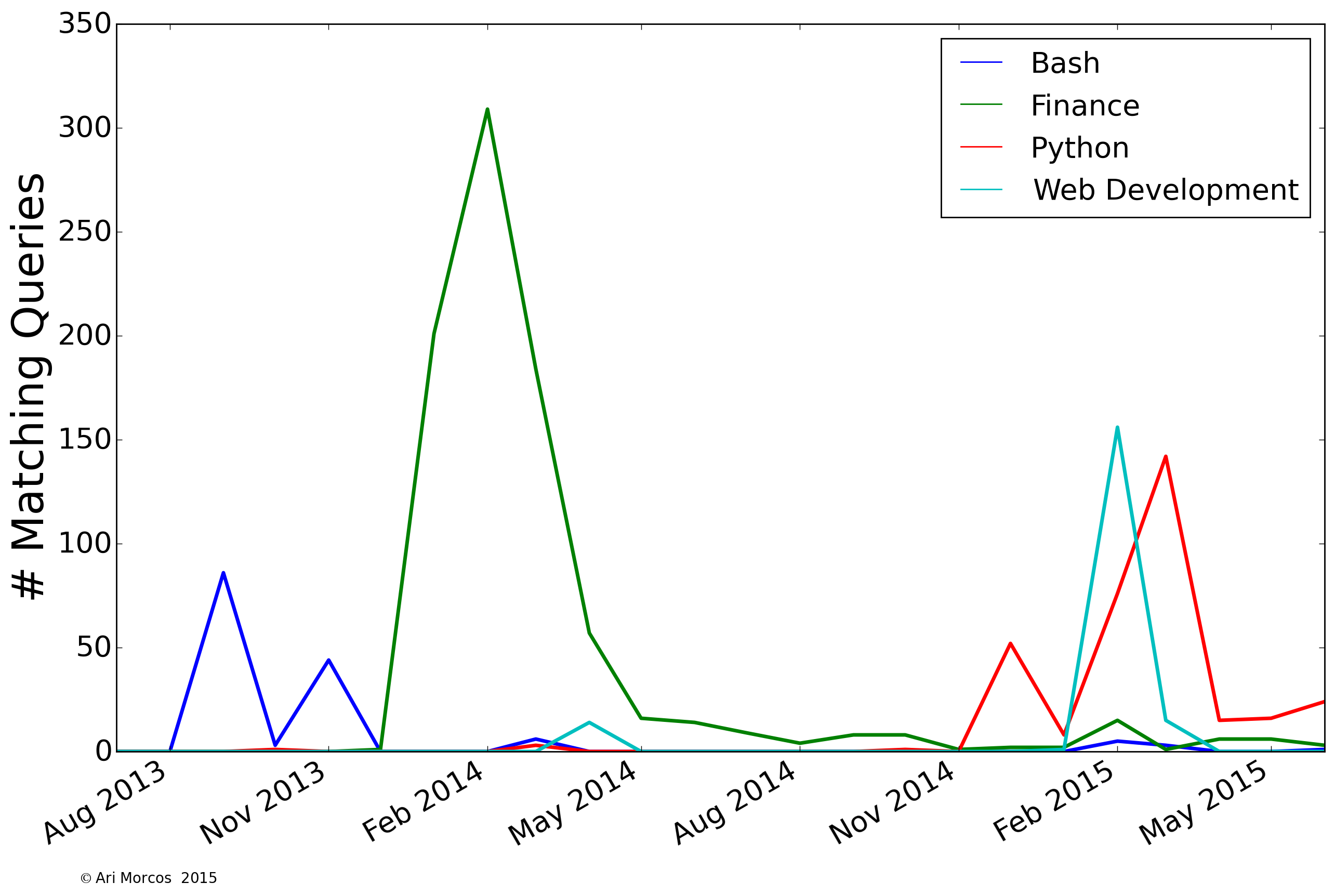
We can immediately see that all of these terms were searched for over short time periods, and not so much outside of that narrow window. I searched for "bash" a lot in late 2013 while I was learning how to use Orchestra, Harvard Medical School's high performance computing cluster for my research. Shortly thereafter, I developed an intense interest in finance and investing, which lasted through the early summer of 2014. I built this website in early February of this year, and therefore spent a lot of time searching for terms related to web development. Finally, I started learning python at the end of last year, and my searches related to that have continued, with a big peak when I undertook my first big project with python on clustering subreddits based on common word usage in March.
We can perform this same analysis for several other themes as well:
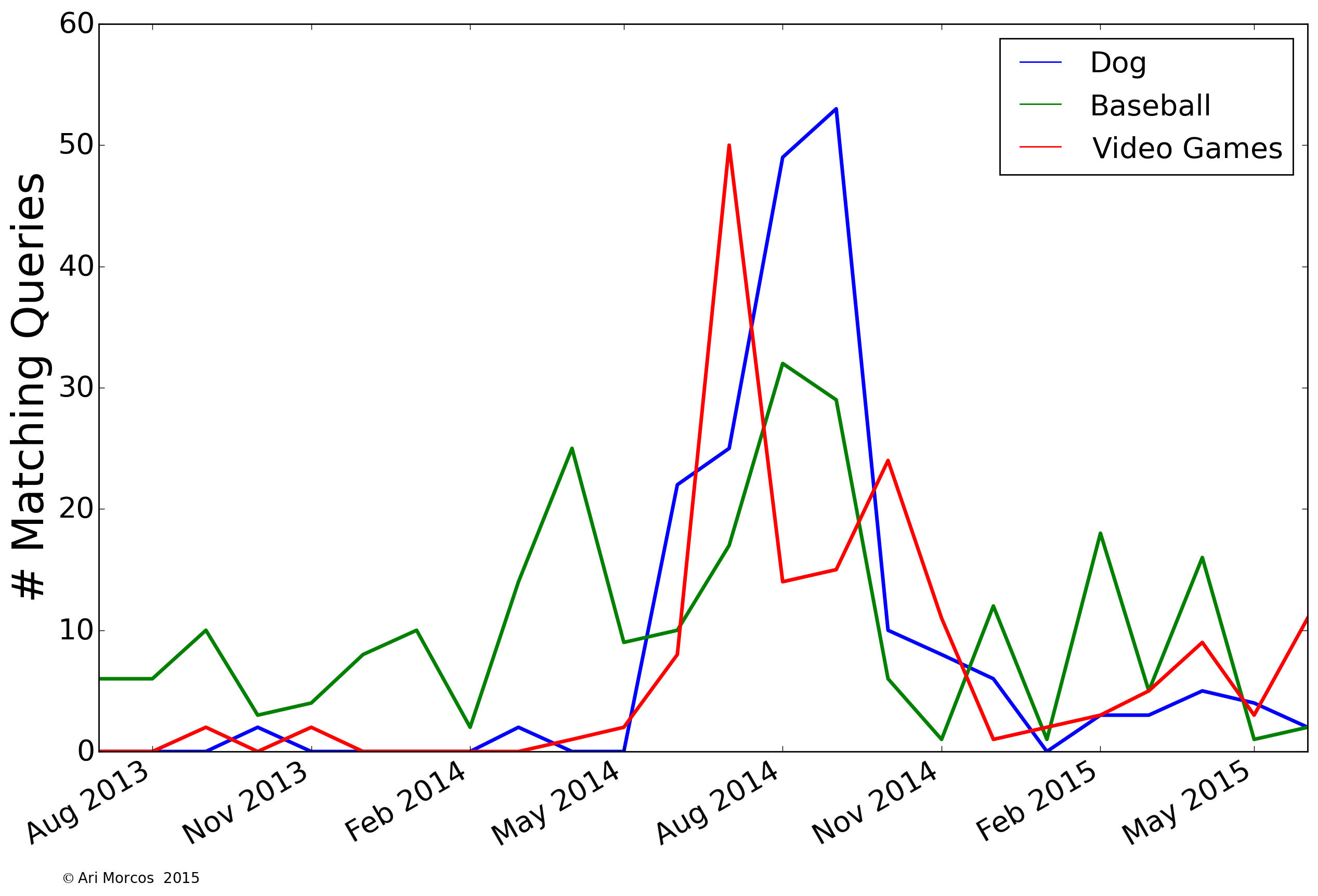
We can see that I searched a lot for "dog" in late summer, 2014, just before I rescued by dog, Dash, who's prominently featured in my about me page. We can also see two search themes with interesting cyclical patterns. First, my searches for baseball ebb and flow with the season, falling off after the World Series in October, picking up again during the Winter Meetings in December, and then finally coming back to life in anticipation of the season starting in April. You can also see that the long season takes a toll on me, as my interest wanes some in early summer before picking back up during the pennant races. My searches related to video games are also cyclical, peaking around E3 in June and the major releases in the fall.
How do my searches change over the course of a week?
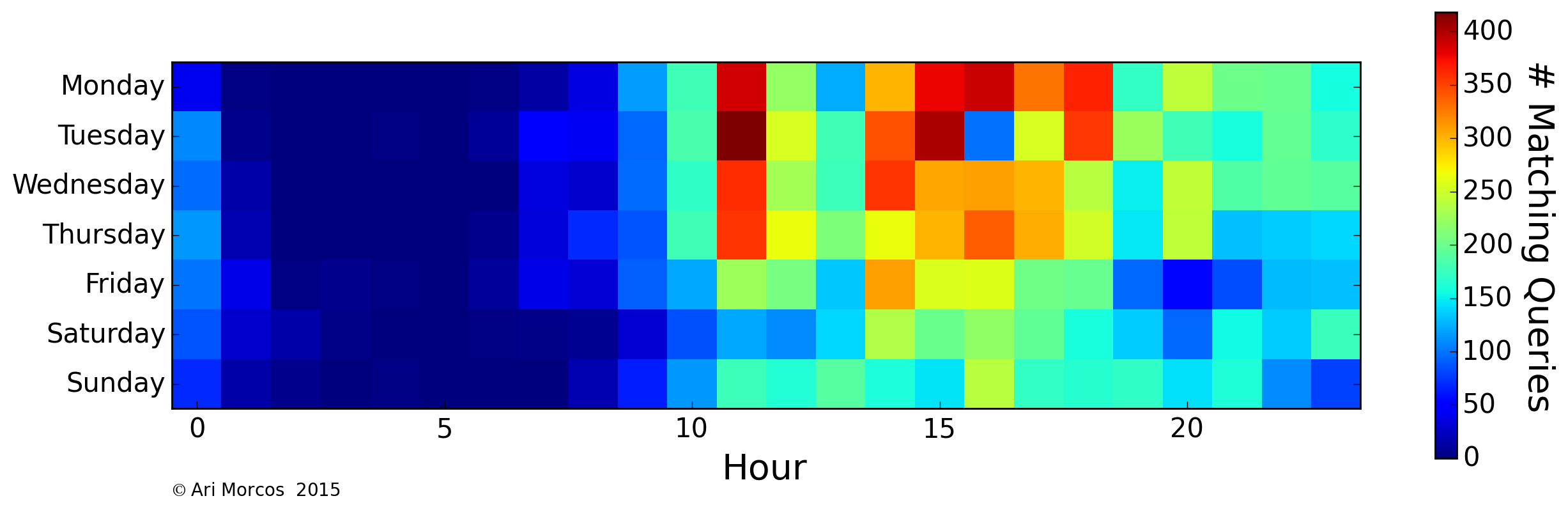
Next, let's look at when in the week I most often search. We can visualize this as heat map, in which each row represents a day of the week, and each column represents an hour of the day. The color of each pixel corresponds to the number of matching queries. First, we can look at all of my searches to get a general idea of when I search the most:
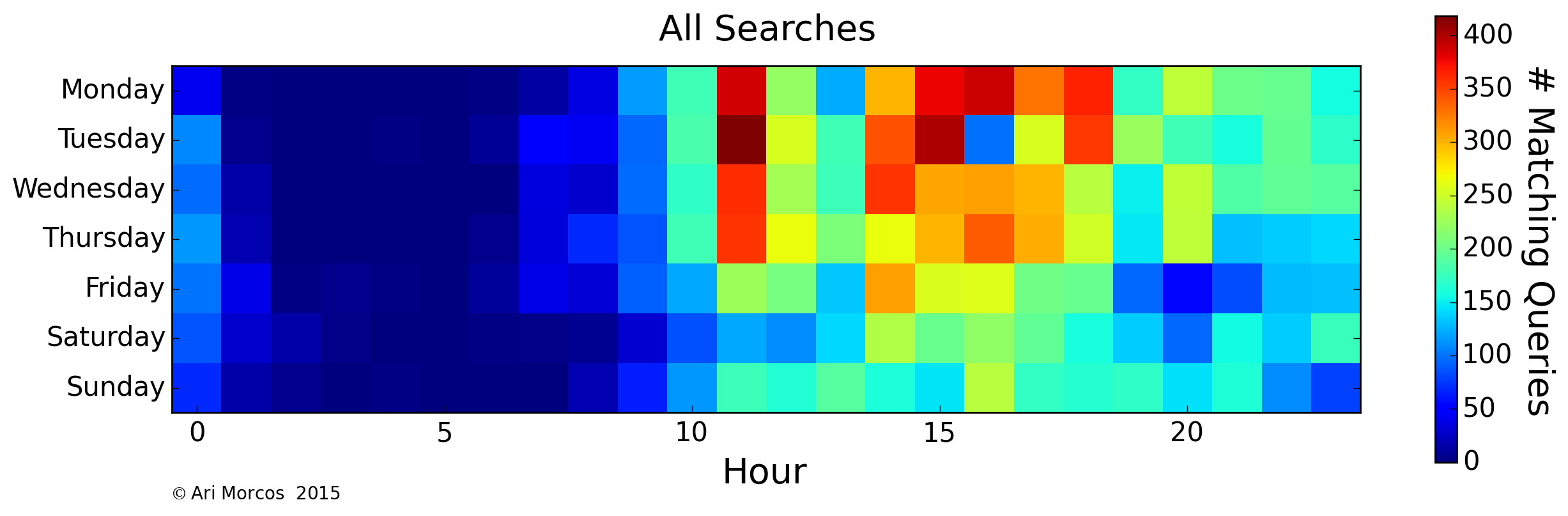
As might be expected, we can see that I search most often during the work day and quite often in the evening, but very infrequently between the hours of 1AM and 8AM, when I'm usually asleep. On average, I search more frequently during the week, but not by a tremendous margin. There is also a single pocket on Tuesdays at 4PM. This lack of searches corresponds to my lab's weekly meeting. Now that we have an idea of what my general search patterns look like, let's look at specific themes. For example: the word, "matlab":

Because I use Matlab primarily for my research, I search for it most often during the day on weekdays. Apparently, I'm also substantially less productive on Fridays. Whoops. On the flip side, I use python primarily for this blog, and my side projects:
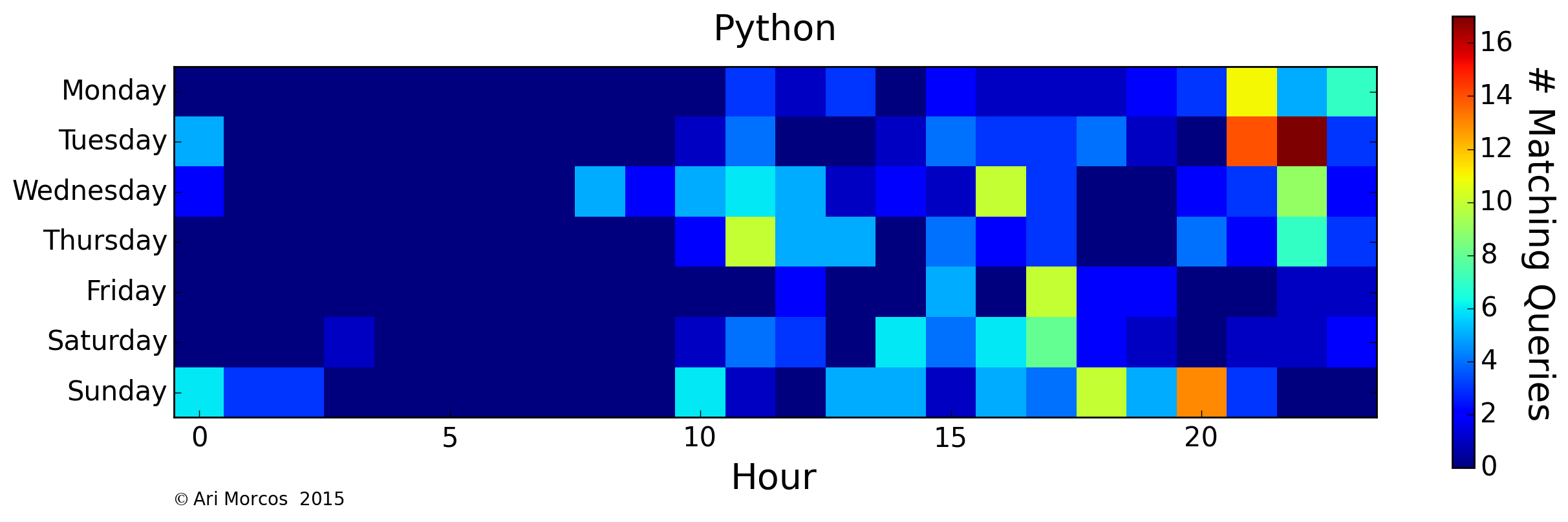
Here, we see an approximately inverted graph, with most of my searches relating to python occurring in the evenings during the week and during the day on weekends. A similar trend exists for operating systems, as I use a Windows 7 PC at lab, and a Mac at home.


Finally, let me leave you with my favorite plot from this analysis. When do I search for terms relating to video games?

Apparently, late afternoons during the week are tough for me, as I seem to usually take a break and search for video games, seemingly looking ahead to playing something when I get home.
Closing thoughts
While perhaps not surprising, it's a little scary how much I could learn about my habits through even a cursory analysis of my search history. Moreover, I tend to be careful about my searches. If I don't want it to be recorded, I use incognito mode in chrome or a privacy-first search engine such as DuckDuckGo. If I didn't have these habits, I might have had to filter a lot more of the results for this post.
Furthermore, these analyses don't even get into the really interesting stuff one can do with search data given the histories of large quantities of users. Applying machine learning tools to these data to make inferences about users must have incredible power, and perhaps justifies the growing tide of Google-phobia. That said, these data also have tremendous power to make our lives easier. I appreciate that my searches are more likely to return what I'm looking for because Google "knows" me. Ultimately, it's up to each of us individually to decide how much we're willing to give away in exchange for convenience.
You may have noticed that this post is titled Part I. That's because I have several more ideas for analyses on this dataset. How often do I search for the same thing more than once and how much time passes in between? How do my queries evolve when I'm having trouble finding what I want? Expect a Part II with these analyses shortly!
You can check out the iPython notebook used to perform these analyses here.

{kind=link}