One of reddit's best features, along with its voting system, is the ability for users to create their own subreddits, forums dedicated to specific topics. There are subreddits for any and every topic one can think of, and redditors know that subreddits quickly take on dynamic personalities. Some subreddits are known for vigorous discussion, while others simply represent a constantly updated collection of entertaining content. Some serve as learning resources for those new to a field, while others are places for debates among experts. Some are incredibly supportive, while others quickly become havens for trolls.
But what defines a subreddit? There are some obvious answers: topic, content type (images, videos, self-posts, or all of the above), and user population. For example, by topic, one might expect subreddits related to video games to be more similar to one another than any of them are to /r/politics. By content type, it seems reasonable to assume that self-post only subreddits like /r/AskHistorians and /r/AskScience are more similar to one another than either is to /r/AdviceAnimals. But are there more subtle differences between subreddits that can be used to group them in meaningful ways as well? Do users of the different subreddits write in distinct, predictable fashion? How much information does it take to categorize a subreddit? As it turns out, not nearly as much as one might think.
Creating subreddit-specific word frequency distributions
To answer the question of whether users in different subreddits write in distinguishable ways, I analyzed the frequency of words used in the comments of each subreddit. Choosing the right number of words to analyze is a bit of a balance. Choose too few words (the, a(n), etc.), and the subreddits will be entirely indistinguishable. Choose too many, and you'll quickly start getting subreddit specific words, such as names, which will trivialize the problem (e.g. "Clinton" is much more likely to appear in a politics related subreddits, while "Bioshock" is much more likely to appear in video game subreddits). For these analyses, I chose to use the 100 words most frequently used across the comments of the top 50 subreddits. This list includes common articles, a lot of pronouns, and a lot of basic verbs. However, there are no words which should be definitively linked to a given subreddit. For example, the 98the, 99th, and 100th words are "going," "want," and "didn't," respectively. You can see a complete list of the words here. Thus, the distribution of these words should provide an intuition into how users write while remaining agnostic to the "jargon" of each subreddit.
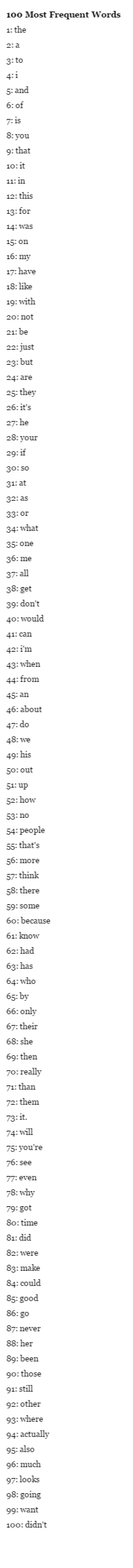{kind=link}
With these words in hand, I analyzed the comments submitted to the 50 most popular subreddits between March 2 and March 8, 2015. If you're interested in how I acquired this dataset, check out this post. To create word frequency distributions for each subreddit, I simply counted the number of occurrences (case-insensitive) of each of the 100 words, and normalized by the total number of words in each subreddit. This normalization step is key, because if one simply uses the absolute counts, subreddits with longer comments (such as /r/AskReddit) will clearly separate from all the other subreddits).
A subreddit distance matrix
As a first pass analysis on these data, I calculated the euclidean distance between the 100-dimensional normalized word distributions for each pair of subreddits, resulting in the following matrix:
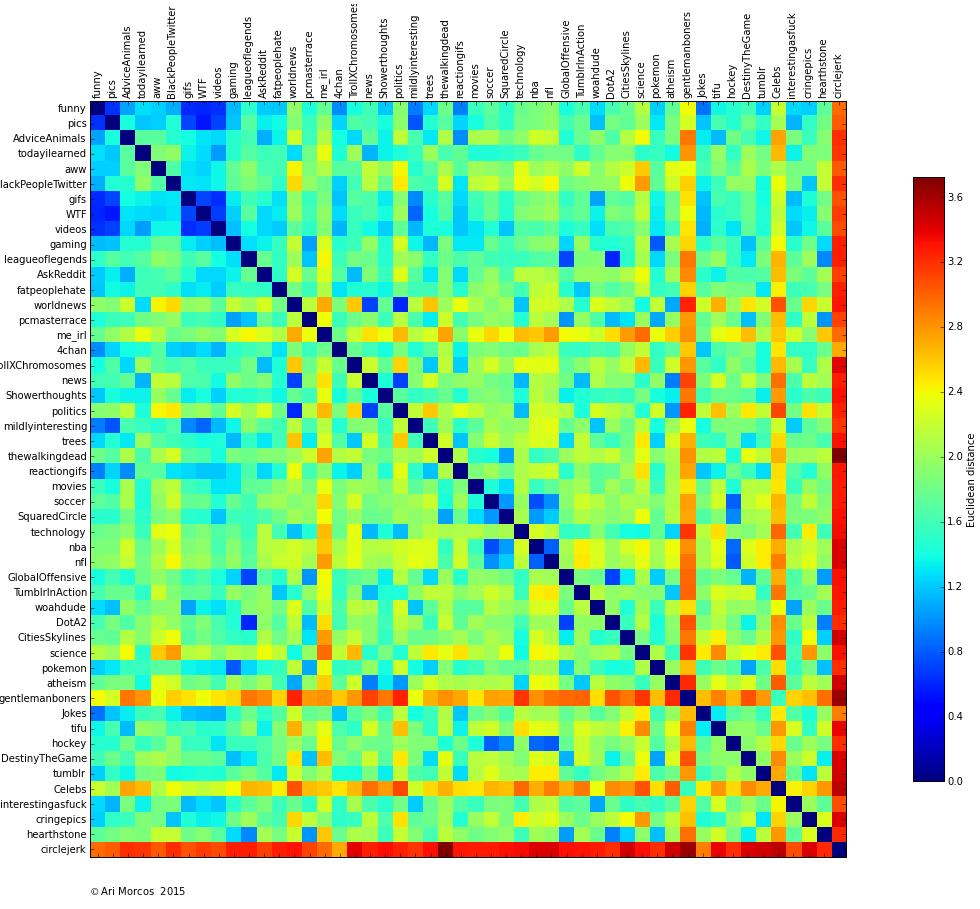
Each point in the matrix represents the comparison between two subreddits. Cooler colors signify more similar subreddits, hotter colors subreddits that are more different. Elements along the diagonal represent a comparison of a subreddit to itself, so the distance is 0. Also note that there's no directionality to these comparisons so the matrix is symmetric.
A few observations pop out immediately. First, there are a few bastions of blue off the diagonal. In a lot of ways, these make intuitive sense. /r/funny, /r/pics, /r/gifs, /r/WTF, and /r/videos are all pretty similar to one another. All of these subreddits link to content as opposed to self-posts, they all are or once were default subreddits, and none of them are known for "serious" conversation.
Second, /r/circlejerk is different from every other subreddit. Third, the sports subreddits (/r/nba, /r/nfl, /r/SquaredCircle, and /r/soccer) are all pretty similar as are the variety of video game subreddits.
There are many more observations to be made from this matrix, but it's a little challenging to quickly grasp the clusters using this technique. Let's try a different method which might make this easier.
Clustering subreddits
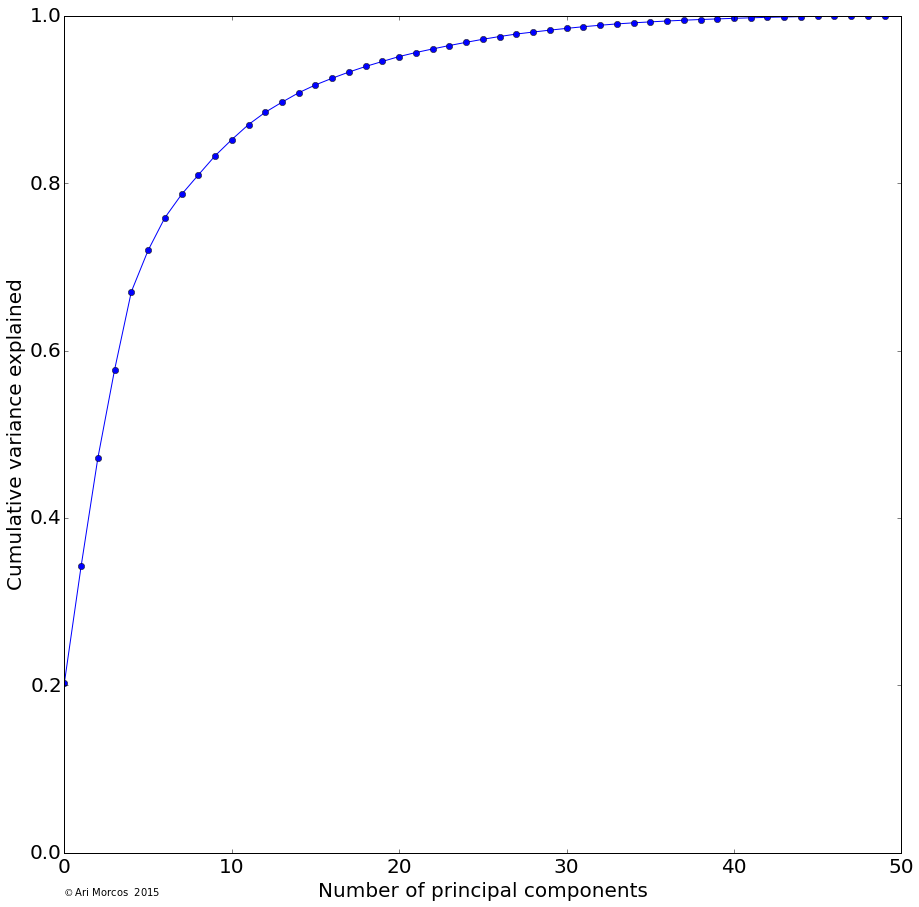
Instead of plotting a distance matrix, it would be substantially more intuitive to plot the subreddits such that there location described their similarity. Unfortunately, we've yet to find a great way to visualize a 100-dimensional space, so I used principal components analysis (PCA), one of the most basic forms of dimensionality reduction, to allow us to better visualize the data. Briefly, PCA is a method which allows us to reveal the underlying structure in the data. While the data may occupy 100 dimensions, if dimensions are strongly correlated, we might only need a few dimensions to describe the majority of the variability. PCA attempts to do this by remapping or "projecting" the data onto these dimensions. As it turns out, in these data, there's quite a bit of structure, as the first three principal components explain more than 50% of the total variance, and the first 15 explain more than 90%.
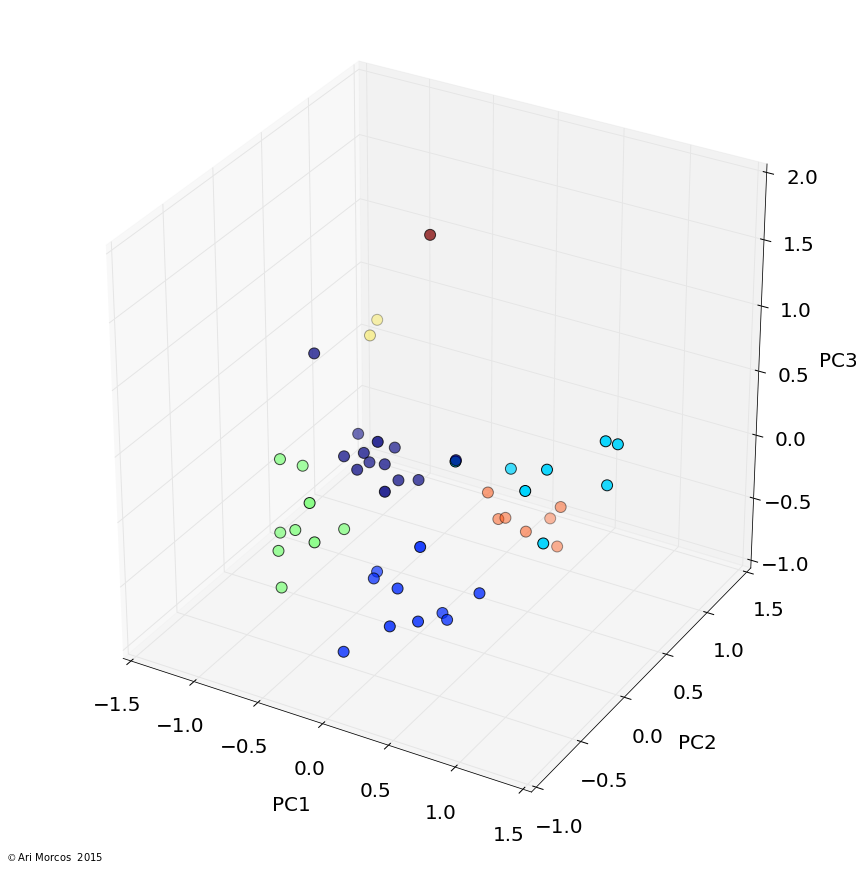
I then used affinity propagation, a clustering algorithm based on message passing, to cluster the data in the first 3 principal components. One really nice feature of affinity propagation is that, as opposed to k-means clustering, it doesn't require you to estimate the number of clusters beforehand. The algorithm clustered the data into 7 nicely separated clusters, as displayed in images below.
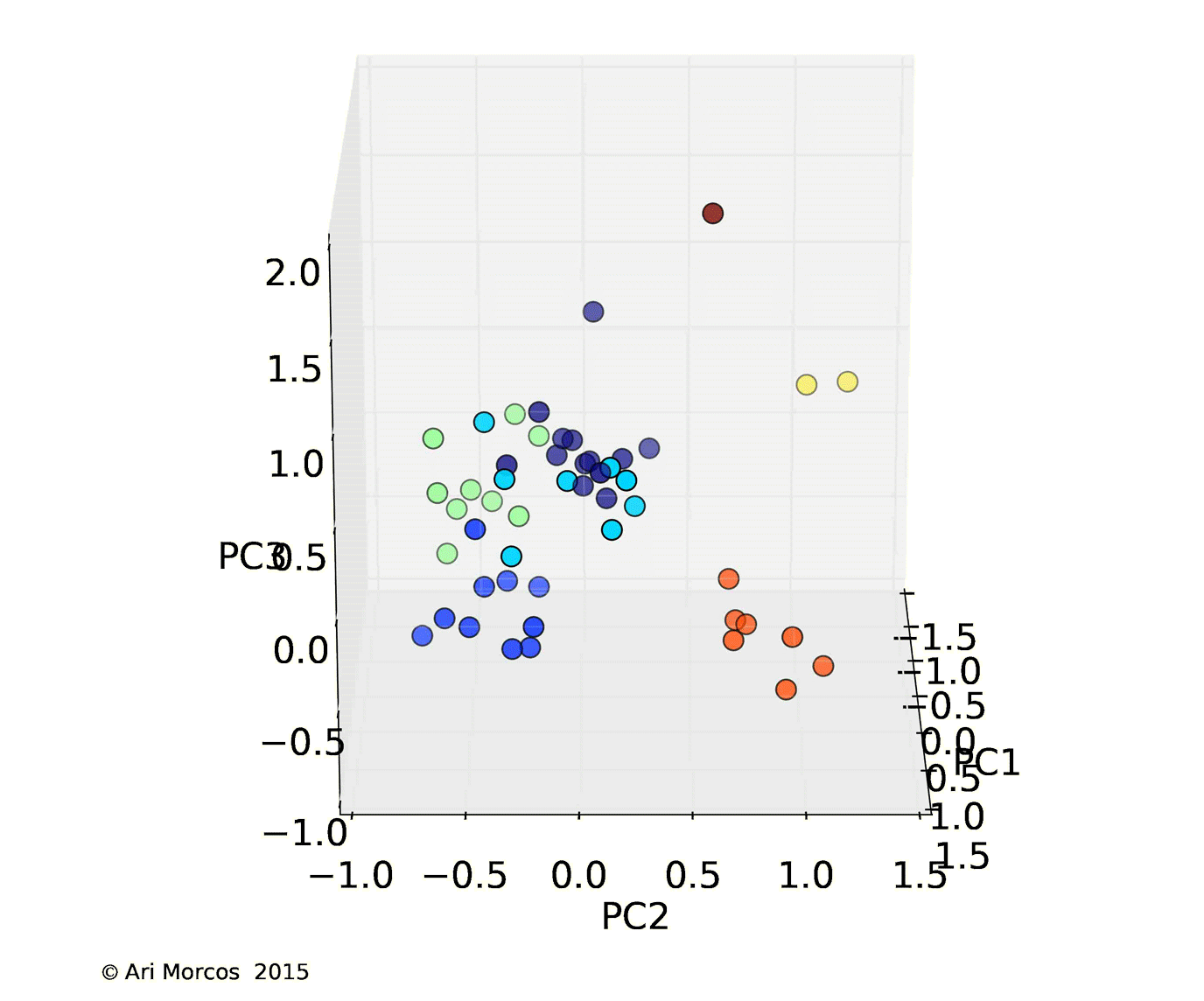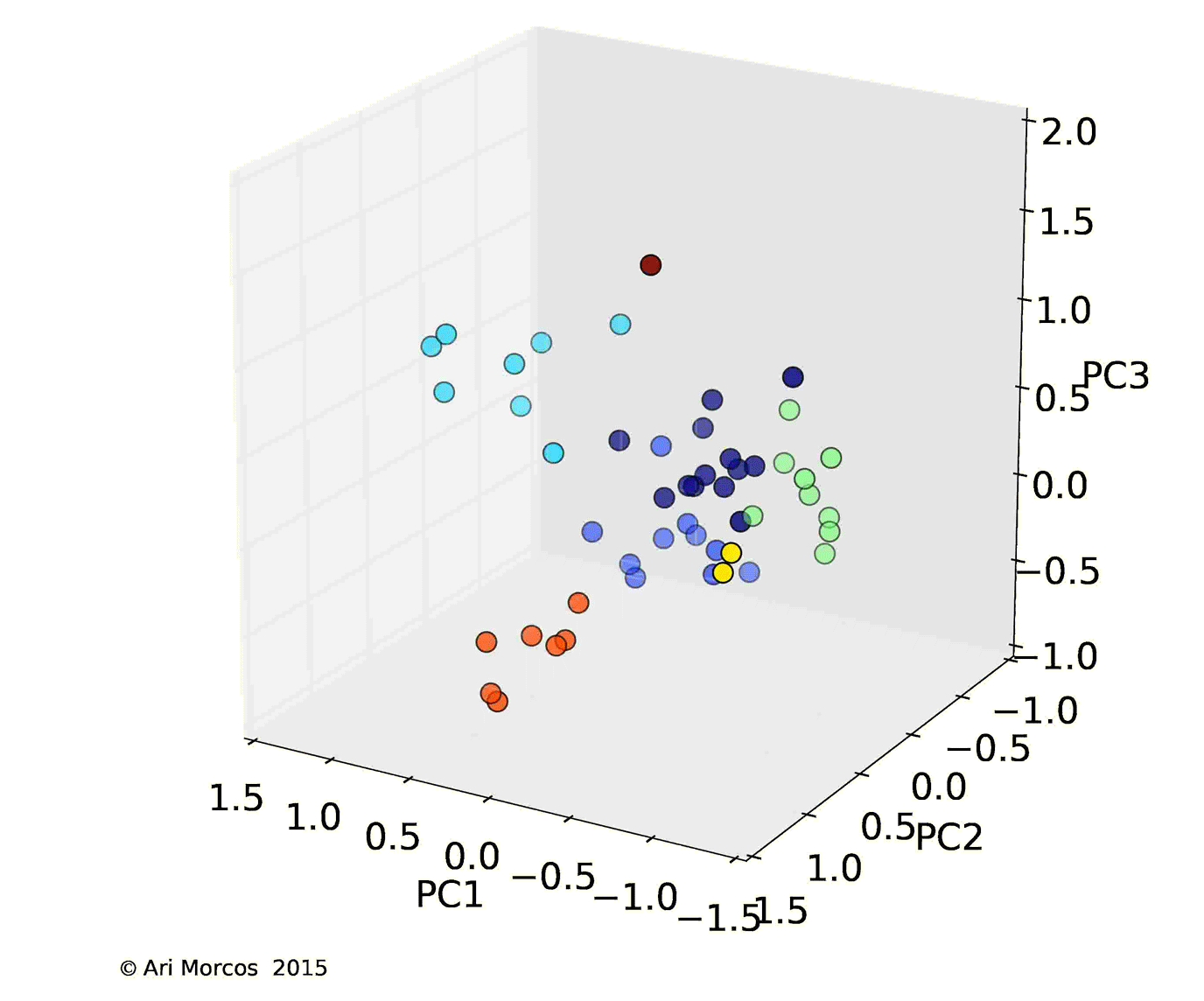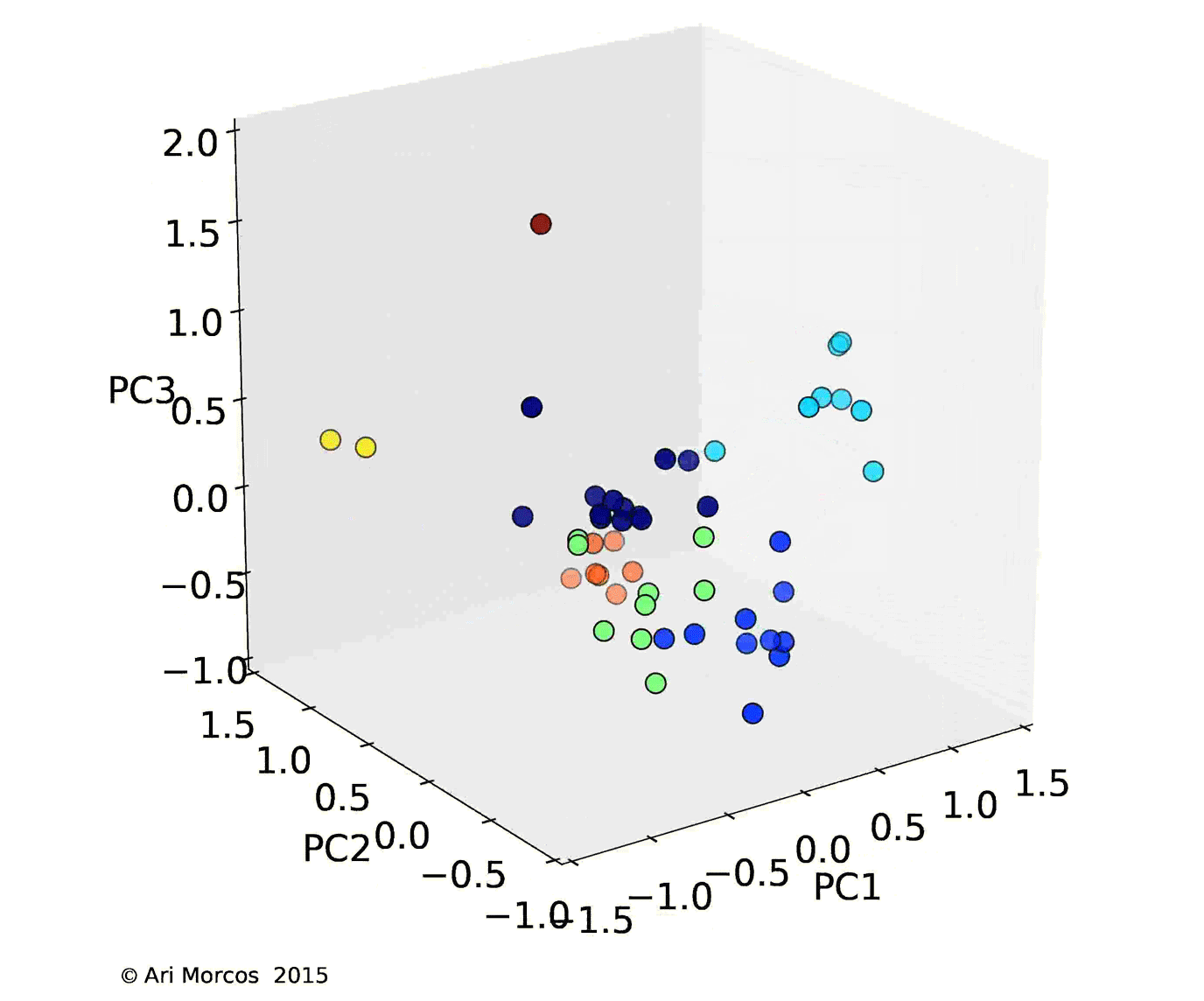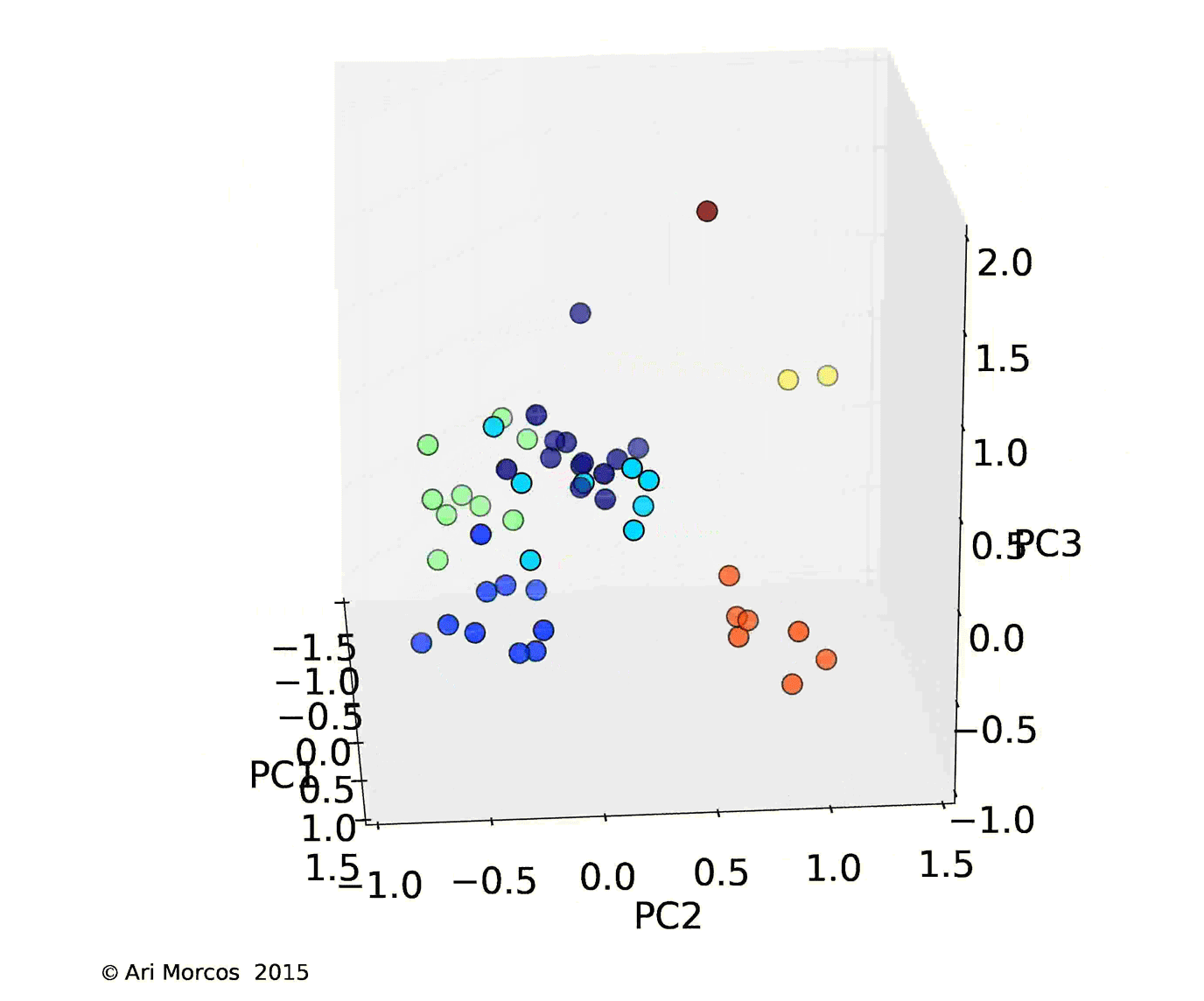
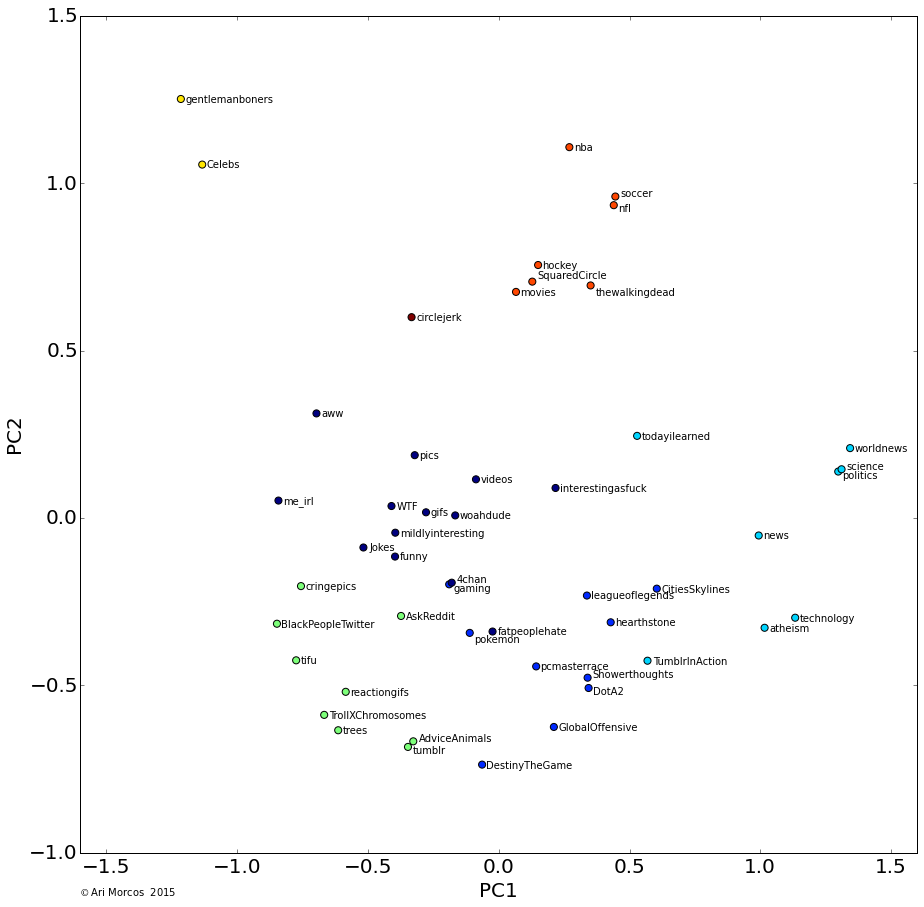
From this image, we can see that, not only does the data cluster cleanly, the clusters make sense. The orange cluster contains all the sports subreddits, the navy blue cluster contains the content subreddits discussed above, the royal blue cluster contains the video game subreddits, the green cluster contains an odd assortment of subreddits with no clear pattern, and the teal cluster contains the more intellectual subreddits.
Interestingly, the most similar pair of subreddits, /r/gentlemanboners and /r/Celebs, define a cluster all on their own, as does /r/circlejerk.
What defines the subreddit clusters?
So we can cluster the subreddits cleanly, but what defines these clusters? As a general overview, we can look at the contribution of each word to each of the principal components.
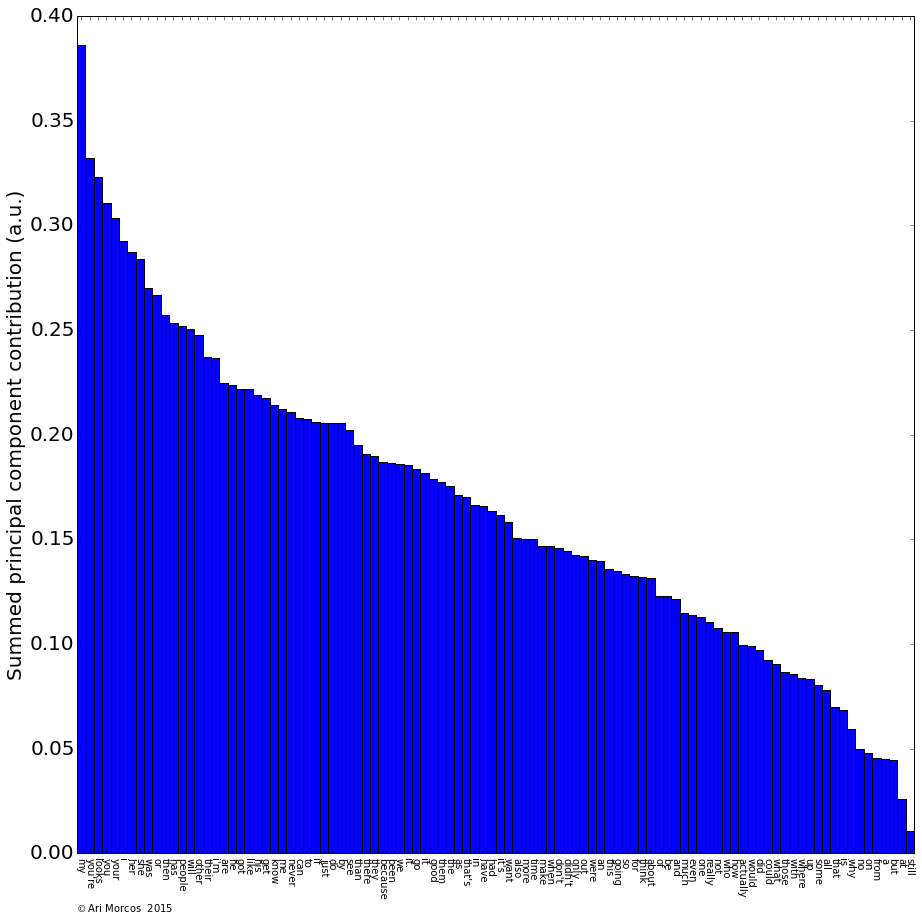
The above plot shows the sum of the absolute values of the contributions to each of the first three principal components. If we look at the words which have the largest contribution, they tend to be pronouns and possessive pronouns (my, I, you, she, her, etc.), along with a few other miscellaneous words like "looks."
But what about individual clusters? To analyze the words that define individual subreddits, I calculated the mean frequency for each word across all the subreddits and then divided each subreddit's distribution by the mean distribution. A value of 1 indicates that the word has the same frequency as the mean frequency for that word. Values above/below 1 indicate that the word is over/underrepresented. So, what does this look like for the gentlemanboners/Celebs cluster?
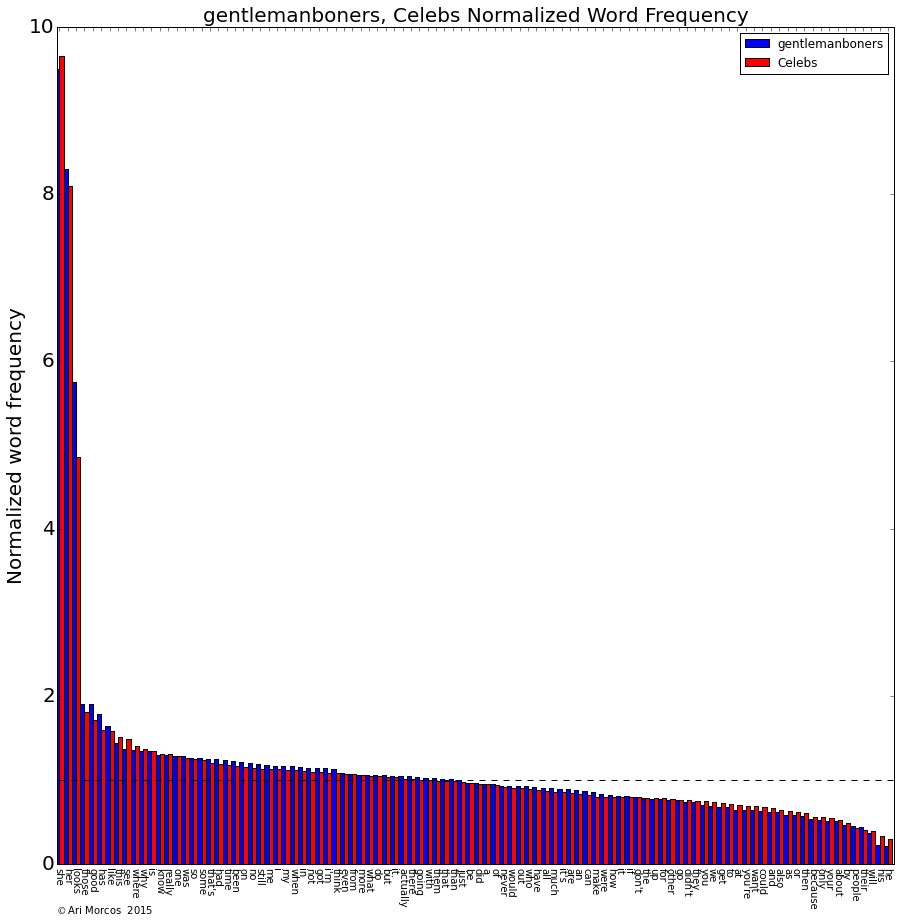
Comically, the cluster is defined by a nine-fold overrepresentation of "she," an eight-fold overrepresentation of "her," and a five-fold overrepresentation of "looks," along with an underrepresentation of "he," "his," and "people." The sports subreddits, on the other hand, are defined by pretty much the opposite phenomenon. Take /r/nfl for example:
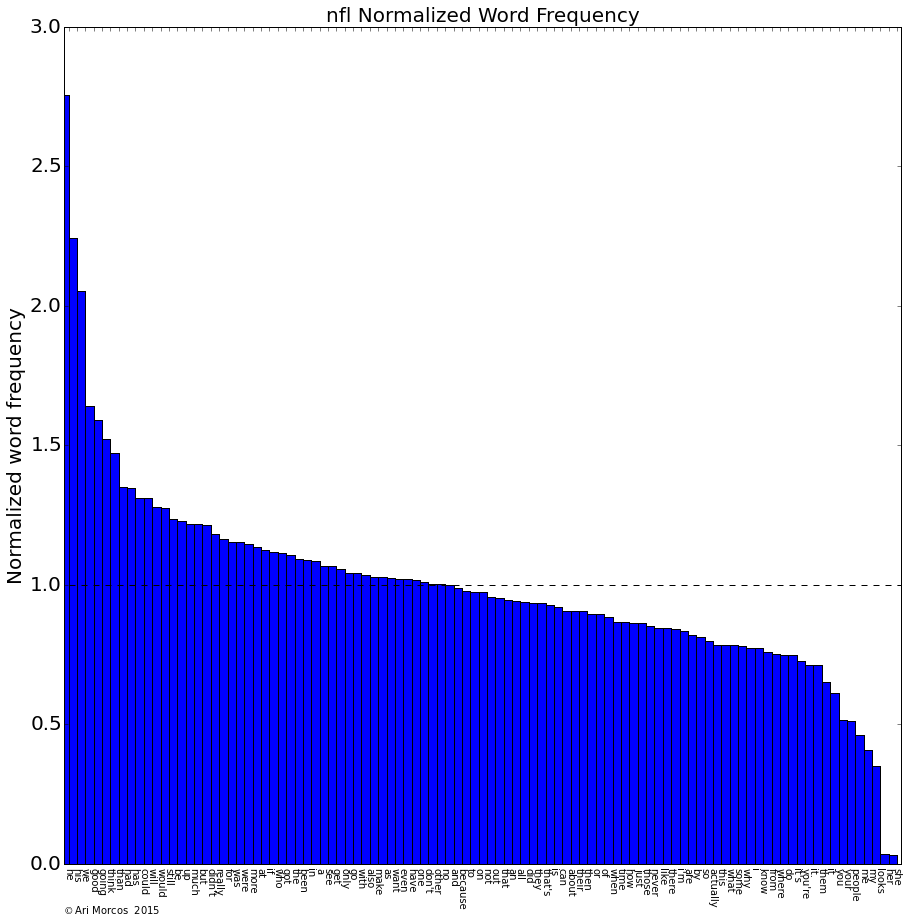
Sports subreddits: overrepresentation of male pronouns, along with an underrepresentation of female pronouns along with "looks." What about the subreddits in the green cluster such as /r/trollXChromosomes?
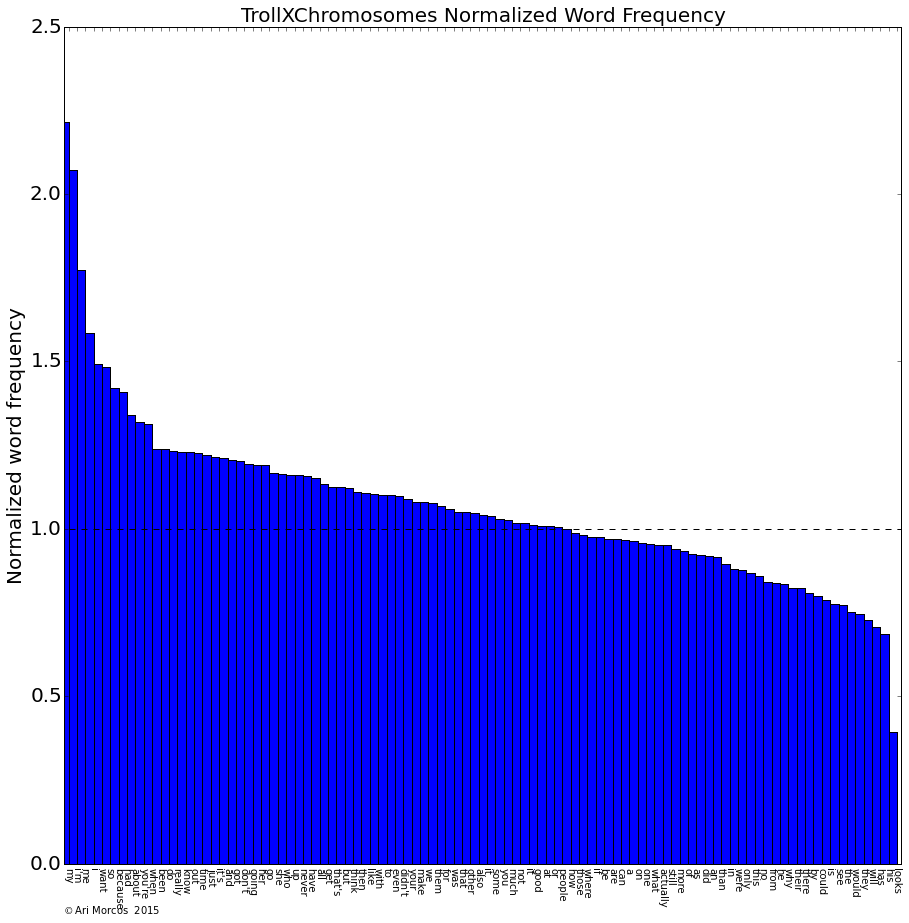
Again, the subreddits in this cluster are defined by pronouns, but this time by pronouns associated with oneself such as "I," "my," "me," and "I'm."
The other clusters are defined by more subtle patterns, and are less dominated by individual words. However, I want to point out one more which I find personally gratifying. What defines /r/science?
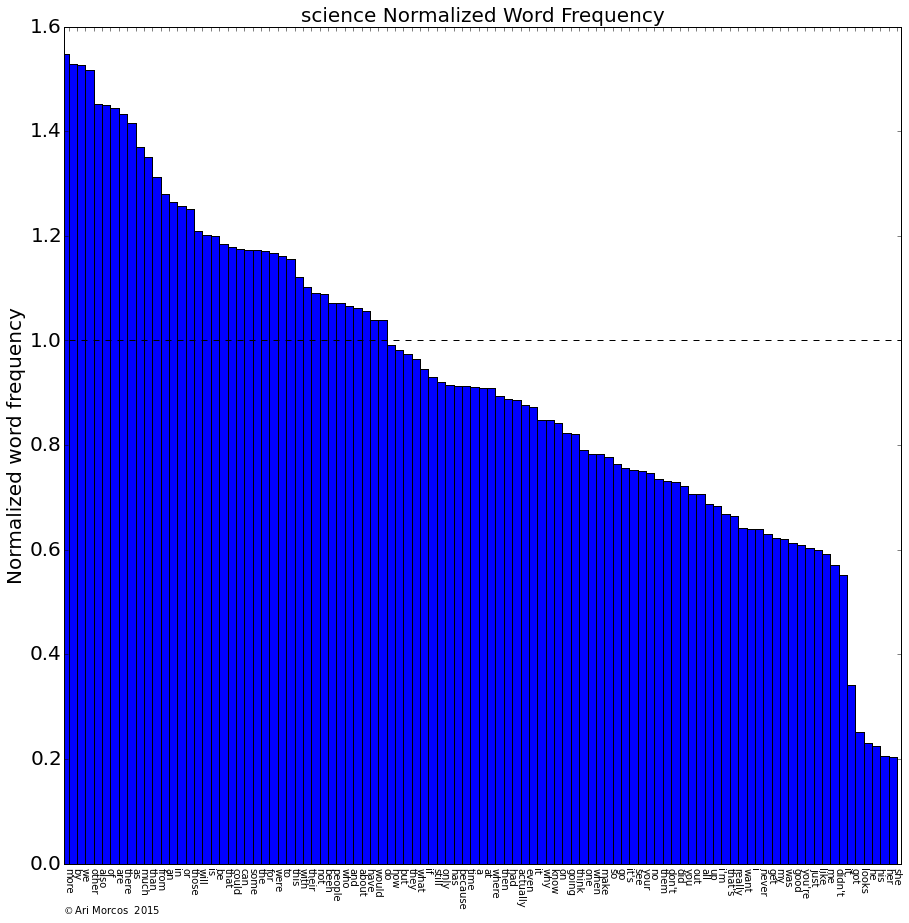
Again, some pronouns, but perhaps reflecting the collective spirit of science, the singular pronouns are all underrepresented while the only overrepresented pronoun is "we."
Conclusions
Overall, I'm quite pleased with how this analysis turned out. Not only did subreddits cluster in a reasonable fashion according to topics, many of the clusters can be defined by differences in just a few individual words, with pronouns having a disproportionate influence. Perhaps most surprisingly, one can categorize subreddits based on just a small subset of words and comparatively little processing. I suppose how we write says a lot about us.
You can check out the iPython notebook used to perform these analyses here.
Updated: 2015-03-27